

Inclusive data analysis: Find the needle and then the haystack
A case study on averages and margins


Marginalized people are often marginalized in datasets. It’s an inversion of what happens IRL: in real life, minorities can’t help but stick out, but in data they’re lumped in with the rest. In data, marginalized people, if they are encoded at all, are often hidden in averages and other aggregate measures; finding those signals requires a mix of commitment and creativity. In this longish post, I’ll (attempt to!) use a case study to illustrate how exactly to do that, which I hope is useful for people who regularly play with data (PMs, marketers, strategists, etc.)
Here a rundown of all the topics discussed:
[Research] Using COVID suicide research to show how marginalized people are under- and/or mis-represented in data
[Case study] How to correct for distortions with quantitative and qualitative methods
[Methodology] Finally, we look at how “small data” can have big implications
Colorblind leading the blind

Averages are misleading. They render the forest but pixellate the trees. This effect is worse for marginalized people who by definition do not experience the “normal” or “average” experience.* A recent story in the NYT shows how this distortion can happen. In it, researchers try to figure out whether suicides have risen during the pandemic. It doesn’t seem like it at first — rates are steady pre- and post-COVID. But other researchers look at data from Maryland and discovered that suicides doubled for Black people but fell by half for Whites — an offset obscuring reality. Indeed, “the results highlight how the experience of vulnerable groups can be missed unless researchers look for them specifically.”
When you analyze the national data, you can see how the analysis is further skewed by the experience of dominant groups, again obscuring the reality:
Among white Americans, men age 45 and older are most likely to die by suicide. Because white Americans have the country’s highest suicide rate, the aggregate data implies it’s a problem that largely affects older people. But among Black Americans, those most likely to die by suicide are men between 25 and 34. And while the age group most at risk has remained roughly the same for white people in recent decades, Sean Joe says, it has been getting “younger and younger” for Black people.
My takeaway for product inclusion is that you have to start with the assumption that people experience life differently because of race, gender, orientation, SES status, and more. And inequality and racism, perhaps the chief scourges of our time, color everything — especially the data we collect.
Sifting for signals of color
So, given that datasets are biased, how can we use our sleuthing powers to learn about all of our users? And more specifically, what can we learn by looking at the averages and margins? Let’s turn to the case study. (Note: the data’s made up, but the examples mirror reality.)

When I first dive into a dataset, I almost imagine myself feeling a sculpture in the dark (a favorite pastime). You feel around, pick it up, put it down, slowly discerning the underlying structure. I channel my high-school stats class, and think: mean, median, mode, and range. And then from there I turn to the outliers. Thanks for indulging me this most labored metaphor. We can move on now.

In this example, our dataset represents text conversations, which are the core service we provide at CTL (trained volunteers chat with texters to de-escalate a crisis). To start, I find it’s useful to pull distributions. I pulled conversions by convo length because we know from research it’s a meaningful variable that is correlated with quality. There are four clear clusters of behaviors. Let’s examine each in turn:
The first thing I notice is that (C) represents a majority of conversations, which clock in ~30 minutes. Beyond that, convos range from lasting 2-3 mins all the way to ~55 mins. What’s happening at the extremes?
The (A) conversations are very short — likely too short for an effective intervention. Here, I look at the corresponding chat transcripts (i.e., the qualitative data). Some conversations were abandoned, which is expected behavior. Other conversations began with Spanish and French words. We don’t currently offer non-English support in America, so the volunteers turned those texters away. I make a note that we might want to auto-detect language in the future — we should track non-English convos for future work and to gauge demand.
(D) conversations are significantly longer. I look at those and discover that they feel different: messages are longer, more formal, with longer gaps between replies. After reading through a few, I discover that the texters are older. Our service isn’t optimized to serve these texters — and longer conversations create an operational drag on capacity.
When I look at (B) conversations, I notice that they’re all blank. I remember that we have a feature that automatically closes out non-responsive conversations at 15 minutes.
Lastly, I take a look at (C) convos. They look fine at a glance. When I cross-reference our quality metrics, I notice that a few have low ratings, but I can’t discern a pattern. I make a note to run this same analysis with a distribution of satisfaction ratings, which might yield additional trends.
As a next step, I’d turn to user research to collect additional qualitative data on our marginalized users. At CTL, we avoid talking to users who have just had a crisis, so instead, we’d talk to the volunteers who fielded those conversations. Fast forward a week, and we learn some surprising things and set some action items.
The Spanish speakers are often immigrants, and we realize that our resources for immigrants are inadequate. Even if we are turning them away, we can direct them to better services. We also realize that we need better tracking, so we update our UI to allow volunteers to tag conversations, thus boosting these signals in future datasets.
Our volunteers tell us that our older texters often struggle with some of our terminology. We make a similar plan to start tracking that. And we update our automated phrases to remove the most confusing words.
As a product team, we determine that we need to do more focused research on those texter segments, and draft a research plan.
By finding the needle in the haystack, you uncover new haystacks altogether.
Small data ≥ big data
The last point I want to touch on is representativeness. Big Tech is biased towards Big Data. It’s true that we need a lot of data to infer statistical significance, but that doesn’t mean that small data isn’t helpful, as Zeynep Tufecki argues in a recent newsletter (everything she writes is gold, btw). The issue is especially relevant to startups and nonprofits, where it may take weeks to amass enough data for even simple a/b tests.
Tufecki shows how small-scale studies could have helped illuminate our understanding of COVID transmission earlier on. The studies have small samples compared to the massive/lengthy RCTs we normally see in medicine. But they show one crucial thing: air flow really matters.
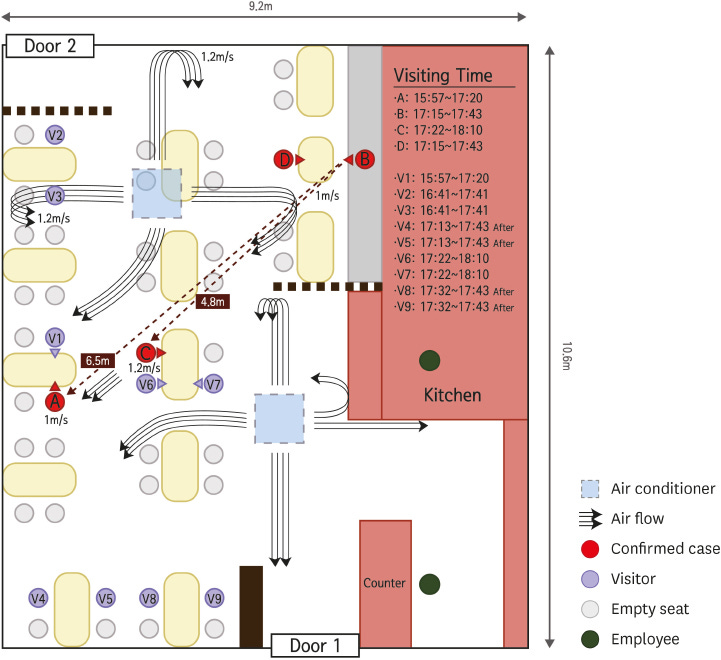
“[These studies] don’t just tell us what happened, they tell us what didn’t happen.”
Similarly, our analysis above gives us directional data on what CTL’s service is not — rather, for whom it is not effective. We learned that we provide a suboptimal service to both Spanish immigrants and older texters. And! We learned we were weren’t tracking this data in a systematic way, and so those blindspots would otherwise persist. We don’t have enough data to say that those negative experiences are universal or statistically representative for those user segments/populations, but we’ve heard loud and clear that we need to double down on research efforts for those people going forward.
The reality is that underrepresented people will always be underrepresented in your data; we must acknowledge our limitations and pledge to keep searching the margins. I’ll leave you with this quote from Anne Jean-Baptise, Google’s product inclusion leader:
I urge you to shift your thinking to think less about who your users are and more about who they could be.
—XML